The ALAMEDA Semantic Knowledge Graph (SemKG) leads the way in advanced data management and access within the ALAMEDA ecosystem. This thoughtfully crafted component is essential for extracting insights from intricate datasets.
The SemKG RESTful API is the primary tool for adding and retrieving data, eliminating the need for complex SPARQL queries. This user-friendly approach streamlines interactions and enhances accessibility.
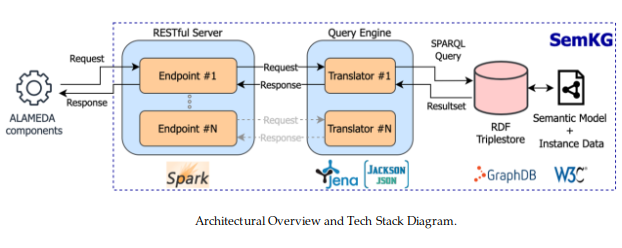
Architectural Framework: A Closer Look
The underlying architecture is a testament to the robustness of our approach:
-
User Interaction:
Users initiate HTTP requests directed towards a designated endpoint on a REST server, implemented using Spark-Java.
-
Query Processing:
The server then transmits these requests to the Query Engine, leveraging Apache Jena, for transformation into SPARQL queries.
-
RDF TripleStore Integration:
SPARQL queries find their way to the RDF triplestore housing the semantic model, powered by Ontotext GraphDB.
-
Result Conversion:
Upon receiving responses from the triplestore, the Query Engine provides the transformation of SPARQL result-sets into structured JSON responses.
-
User Feedback Loop:
The JSON responses seamlessly return to the end-user through the REST server, completing the cycle of data access.
Efficient Data Integration and Expert Presentation
The SemKG seamlessly combines data from various sources, including AIH services such as Facial Emotion Recognition, Gait Analysis, Mood Estimation , Conversational Agent, and Well Mojo. Through SemKG endpoints, knowledge is delivered to the Experts Dashboard (ED) for semantic data visualization and decision support. This flexibility ensures the system's readiness to incorporate new components, maintaining its position at the forefront of healthcare technology.