Emotional tracking of patients can play a significant role in healthcare, since it may assist clinicians to easily monitor the progress of their patients, remotely. With the use of smartphones or other smart devices, meaningful insights related to the health condition can be collected from patients.
To this end, we developed the Mood Estimation Android App, an application that monitors the face of the patient while they interact with other mobile applications, and predicts their emotions based on their facial expression.
Mood Estimation Android App’s main component is the computer vision algorithm, which takes as inputs the video frames coming from the front camera of the smartphone, and estimates the mood of the user. More specifically, we trained the mini-Xception deep learning model, which is trained to recognise in real-time four facial expressions: ‘positive’, ‘negative’, ‘neutral’ and ‘other’.
In this hub, we provide only a simple API that includes the mood estimation algorithm (and not the whole android application).
Mood Estimation algorithm Pipeline:
The API takes as input a video frame or an image. The first step of the pipeline includes the detection and localization of the user’s face within the video frame. For the face detection, we use the Multi-task Cascaded Convolutional Networks (MTCNN) algorithm. MTCNN model locates the face of the user and draws a bounding box around it. The region of interest is cropped and fed to the emotion recognition model, which outputs the prediction regarding the emotional state of the user.
For the design of our deep learning model, we experimented with different computer vision models, like MobileNetV1, MobileNetV2 and mini-Xception. Several different architectures and hyper-parameter combinations have been tested and assessed with regards to both their prediction accuracy and latency for real-time inferences. After comparison, we concluded that miniXCEPTION demonstrated the best prediction performance and the shortest latency.
Specifically, Mini-Xception proved to be the best choice, since it achieves the best trade-off between model size, inference time and prediction accuracy on test and real-time data. Its size is less than 1MB, the weighted F1 average score equals 0.72 and its prediction accuracy on live data reaches 70-75%.
The architecture of mini-Xception starts with two Convolution layers (which are followed by Batch Normalisation and ReLU layer), followed by four residual blocks. Each block contains a convolution layer on the skip connection side, and the other side consists of two separable convolutions followed by a Max Pooling layer. All convolutional layers are followed by Batch Normalization and ReLu layers. At last, follows a convolutional layer, a Global Average pooling layer and the final classification takes place at the softmax layer.
The optimal model was trained from scratch for 300 epochs with batch size=64, and initial learning rate=1e-3, which was gradually reduced based on Reduce Learning Rate on Plateau technique. The Adam optimization algorithm was used for training and for regularisation we applied the L2 regularisation method.
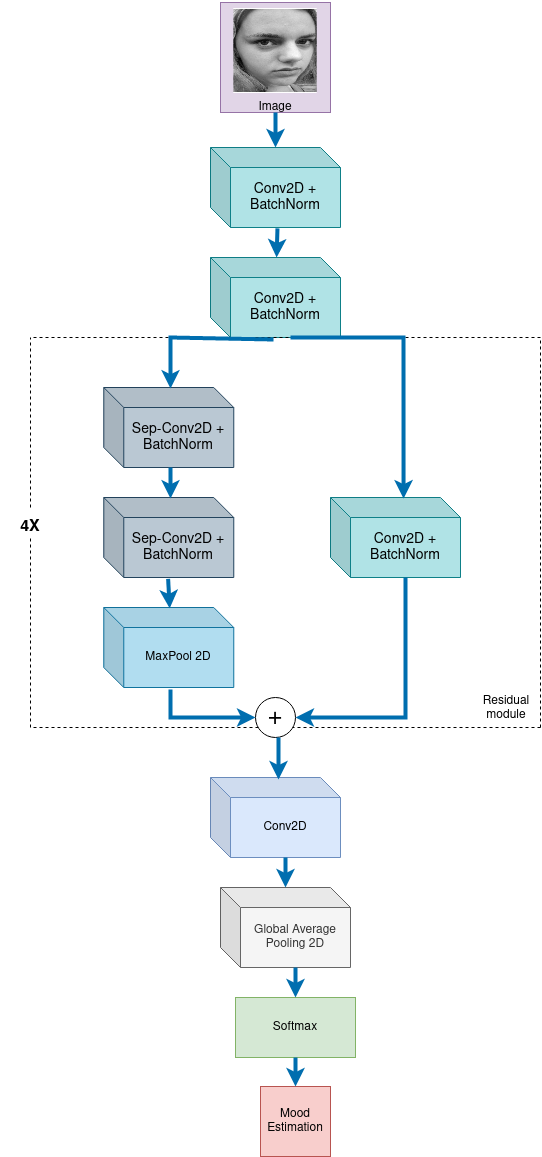
Figure 1: Architecture of mini-Xception model
The API receives as input an image or a video frame (one at a time) and feeds the data into the model. The model outputs four prediction probabilities, one for each possible mood (‘positive’, ‘negative’, ‘neutral’, ‘other’), and the final mood prediction is the one that scores the highest probability.
The Mood Estimation Android App has been developed following industrial standards. In this sense, the toolkit has been packaged and uploaded to the AI Toolkit as a dockerized container. It requires the following commands to open ports and run the model:
-
Login to container registry using guest account:
docker login gitlab.telecom.ntua.gr:5050 -u alameda_ai_toolkit_registry_guest -p ByeYyNesUxqQGs91FzzW -
Pull and run the docker image:
docker run -p 8000:8000 gitlab.telecom.ntua.gr:5050/alameda/alameda-source-code/ai-toolkit/meaa -
Logout from container registry:
docker logout gitlab.telecom.ntua.gr:5050
The docker image enables an API which includes one POST endpoint named “/upload-meaa-image”. The endpoint accepts an image as input and returns the results of the analysis.
Our dataset includes multiple and various facial expressions within each category, in order to create a dataset that represents well the different human facial expressions. Facial images are hard to be found available online, due to the strict copyright licences. For our model training, we collected facial images of people with various facial expressions, from different ages and ethnicities, with and without accessories, and faces under different lighting conditions. Our dataset is a combination of data collected from different sources like Kaggle (FER 2013 dataset , Jafar Hussain Human emotions dataset) and other open source databases such as Unsplash, Pexels and Pixabay.
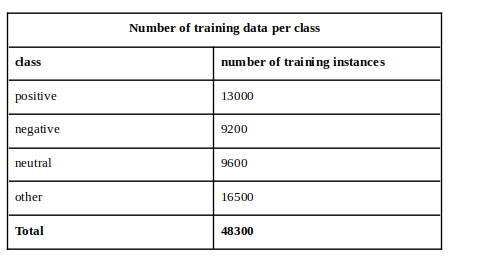
The model was trained with a total of 48300 images. The number of training data per class is broken down us follows:
Following we provide also some samples from the dataset that we used.


Fig. 2. Sample images from the training dataset